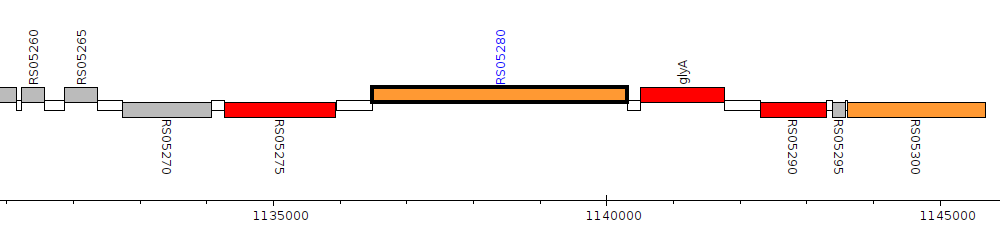
Pseudomonas sp. StFLB209, PSCI_RS05280
Cytoplasmic
Cytoplasmic Membrane
Periplasmic
Outer Membrane
Extracellular
Unknown
Sequence Data
| Strain | Pseudomonas sp. StFLB209 DNA, complete genome. [Details] | |
| DNA Sequence Upstream of Gene |
AGCCATAAAGAAGCAATTATTCAGATTCAGAGCAGCAAAATTGCGCGGGCCGCGCGACGCGGTCGGAACACCGGGCAGGCTGCATTGCGTACGACAAACA AGCGCCACTCAACTGCGCTCAGGGTCGGCAAGCTTAACCCAAGTCGGCGGACGCTGGCAGGGGGGCTGCCCGGCGACAGCCCGAAATCCGCCGTTACGCC GCAGGCAGATACCGCCCTGGCGATATGACTAAAAAAGGTGCAGAAAACCCCTTGAACAATGCCAGATCCGGCTTAATTCTTTGCCGGTCCTTGCCGAGTA ACAGTTACGCGCCTTGAATTGATCAAATGCGAAGTGAAATACGGCAAATACAACCAACCGAACGGGCCGACAAACAGGCGTGACCACCAATAAACGCTGG CACTTAGCCACAACTAAAGGCATGCTAGCCGCCATTTGGGCGCCCGGCTTATAGTGCAGGCTGCATTCGCTGCTTCAGTCCAGTAGTCAGGAACATCGAC
|
|
| DNA Sequence for Gene |
>PSCI_RS05280
TTGCCCACACCAACGGCTTCTACATCATCGCGTAGCGTCAAGAATTCCAGTCAACTGCCTGTGCGTGGTTCACTGAAAGGCGCGTTGGCCGCTCTGGTGT TGGTGATGCTCGCCCTGTTGCTGTGGCAATCCTTCGAGCAGTTTCAACAGACTCAAGAGCGTCAGCGCCAGCGCAGCCTGGACTACAGCATGCAGCTGGC AGACCGCCTGAGCCTGAACCTGACACTCAGCGCCCAGGTCAGCGTGAGCCTGCTGGATGAGGCGGTCAGCGTCGGTCAGTCGCTGGAGCAGCCCTCGACC CTGGACAACCTGCGCCAGGCGCTGCCGGCCCTGCAAAGCGTGGCCTGGCTCAGCCCAGCCGGCGATATCATCAAAGACAGTGCAATGGGCGCCGGTGACG CAGCCTTTCTCAAAGAGCAACTGCGCAAAGCCCAAGGCAAGCCGTACTACTACACCAACGCCAGCGACGGCCGGCTGGTTTACCTGTTGGTCCGTCAGGC GGGCGGCATTACCGGTGACTACTGGGCATTGCGTCTGGGCCGGGAGGCACTCAAGCCGCTGACCCAGCAACCGTCCCACGACTTCATGCACCTGTGGCGC CTGGAAAATCGTGACCAGTCGCAGATTATCGCCCGTGACGGGCATCGCAGTAATGGCAACCTGCAAACGGTGCTGCTGCAACCGATCAGCAACAGCGACT GGCAACTGCATGGTTTGTTCGATGCCCGGCAAGAGCGCGAGGCGCTAGTGTTGCCACTGATTTTCAAGTGCGTGCTGGCCATGATGTTTGCCATCCTGCC CTTGATTACCCTGTTTGGCTTGCGTCGCCGCCAGACCCAACTGGTTGAAAGCCGCCGCCGTTATCAGGGTATTTTCGAGGGGGCAGGCGTTGCCATCTGC GTGCTCGACATGTCCGCGCTGTTTACCTTGCTCGACAGCTTGCAAGTGCGCAATGCCGAGGATCTGGACAGGCTGATCAAACACCAGCCCAGCCAGTTCA AACGGCTGCTCCAGCAATTGCACATCACAGAAGTCAATCAGTTCGCGCTGGACCTGCTGGGTATCGAGAACAGTCAGCAGGCCTGGGACTCGCTGATCGA CGCAAACCCGAGAAACCCCGCAGGCCCAGGAACACGGATCATCCGCGCGGTCCTTGCCAATGAGCCGAGTCTGGAGCTGGAAATTCGCCTGACCCGTGAC GCTGGTGAAGACCAGCATCTCTGGCTGGTCATGCGCCTGCCCGAAGAGCAGAGCGACTACGACTCGGTGATTCTCAGCATTGGCGACATCACTAGCCGCA AGCAGATGGAACTGTCGTTGCTGGACCGCGAAAGCTTCTGGTCCGACGTGGTTCGGACCGTGCCCGATCACCTGTACGTGCAAGACGTGCCCAGCCAGCG GATGATCTACAGCAACCACCATCTGGGGCAGACGCTGGGTTACAGCAAGACTGAACTGCAAAGCATGGGTGAGTTTTTCTGGGAGTTGCTGCTGCACCCC GACGATGCCAGCAACTACCGGGACATGCGCCTGCGCCAACGCCATCATGGGCACAACGAACTGCTGCAATGCGTACTGCGCTTTCGCGACTGCCAACAGA GCTGGCGCCATTTCGATATCCGCGAACAGGCGATGGCCTGGGACAAGGATGACCAGGTCACGCGGATCATCGGTATTGCCAAAGACATCACCCACCAGGT GACCGCCAGCCAGTCGCTGCGCGACAGCGAACAGCGCTACCGGATGCTTGCCGAAAGCATCAGCGACGTTATCTTCTCCACTGATCGGGGTCTGGAACTC AACTACGTCAGCCCGTCAGTCGAAACGGTACTGGGCTACAGCGCCGACTGGATTGTCCGCAATGGCTGGAGCGCGGCGCTGGCTAACCCGCAGCAACTGA CCGGCATCTACAGCCTGATCGTTCGTATCCGCAAAATGTTGAACAAGCCGCACGACCTGGAGCGGCTGCGCAACGAAGTGCCGACCCGTCAGTTCGTCTT CGATTGCCTGCGCGCCGATGGCCGCAAGATTCCTATTGAGCTGCGCCTGGTACTGGTCTGGGACGAGCATGGCAGTTTCGAGGGCATCCTGGGCGTCGCC CGCGACGTCAGCCAGCAACGCCGGGCTGAAAAAGACCTGCGCATGGCGGCTACGGTTTTCGAGCACTCGACTTCCGCGATCCTGATCACCGACCCGGCCG GTTACATCGTGCAGGCCAATGATGCTTTCACCCGGGTCAGTGGCTACGAGGTCCACCAGATCCTGGACCAGTTGCCGACCCTGCTGACCGTAGAGCACGA AGAGGCGCACCTGCACCAGGTGCTCCGGCACCTTAACCAGCGCGGCAACTGGGAAGGCGAGGTTCAGCTCAAGCGCCGCAACGGCGAGCAATACCCGGCC TGGGTCGGGATCACCGCAGTCCTTGATGATGAAGGCGACCTGGCCAGCTATGTGTGCTTCTTCAGCGACATCAGCGAGCGCAAGGCCAGCGAGCAGCGCA TTCATCGCCTGGCCTACTACGACGCCCTGACCCACCTGCCCAACCGCACCCTGTTCCAGGACCGCCTCCATTCGGCATTGCAGCAGGCCGAGCGCCAGAG CGCCTGGGTGGTGCTGATGTTCCTCGACCTCGACCGTTTCAAACCGATCAACGACTCGCTCGGCCATGCCGCCGGCGACCGCATGCTCAAGGAAATGGCC AGTCGGCTGCTGGCCTGCGTGACTGATGACGATACCGTGGCACGCATGGGCGGCGACGAATTCACCCTGCTGCTGCACTCCGGCGCTACCCGTGAGGTTG CCCTGAACCGCGCCATTCATGTGGCCGAACAGATTCTCAACAGCCTGGTCACGCCGTTTGTTCTGGAGGGCCGCGAGTTCTTCGTCACTGCCAGTATCGG CATTGCCCTGAGTCCCCAGGATGGCCATGAACTGAGCCAGTTGATGAAGAACGCCGACACGGCGATGTATCACGCCAAAGAGCGCGGCAAGAACAACTTC CAGTTTTACCAGGCCGACATGAACGCAACCGCGCTGGAACGCCTGGAGCTGGAAAGCGATCTGCGCCACGCGCTGGAACAGGAAGAGTTCGTGCTTTACT ACCAACCGCAGTTCAGCGGCGACGGCAAGCGCCTGACCGGCGCCGAGGCACTGCTGCGCTGGCGCCATCCACGACGCGGGCTGGTGCCACCGAACGACTT CATTCCAGTGCTCGAAGAGCTTGGCCTGGTCATGGAAGTTGGCGACTGGGTACTGGCCGAGGCCTGCCGCCAGCTCAAGACCTGGCACCAGGAACGGGTT CGGGTGCCGAAGGTGTCGGTCAATATTTCTGCCCGTCAGTTTGGCGACGGGCAACTGGGCGAACGCATCGCTGCCACCCTCAGGGACACCGGGCTGCCCC CGGCCTGCCTGGAGCTGGAACTGACCGAAAGTATCCTGATGCGTGAAGTCGGCGAAGCCATGCAGACCCTGGCCGGCCTCAAGAATCTCGGTTTGAGCAT CGCGGTTGACGACTTTGGCACCGGCTACTCATCGCTCAACTACCTCAAGCAGTTCCCGATCGATGTGCTCAAGATCGATCGCTCCTTCGTCGATGGTTTG CCCTCGGGCGAGCAGGATGCACAGATTGCCCGGGCGATCATCGCCATGGCGCACAGCCTGAACCTGTCGGTGATCGCCGAAGGCGTGGAAACCCACGAGC AACTGGACTTCTTGCGCGAGCATGGCTGCGACGAGGTACAAGGCTACCTGTTCGGCCGCCCGATGCCGGCCGGGCAGTTCGAGGCCCAGTTCAGCAATGA CGCACTGTTCATGCTGGATTGA
BLASTN Search
|
DIAMOND BLASTX Search (DIAMOND is faster than BLASTX)
|
|
| DNA Sequence Downstream of Gene |
AGCGGCGGCAGGCGGCTTCAGCCGCGATGGGGTCAGGCCAGGCACAGCAGAGGTGTCGCCTGGTCAATGTTCGCGGATGAATCCGCTCCTACGAGCTTGC AGCTGCTTCACCCGACGGATGAGGCCCTTTCATATGCCAGAGATTCTCTGATGGGGTAGAATGCCCCCCTTTTCCGCTCCAAGCCCTCGAGGACAGCCAT GTTCAGCCGTGATTTGACTATCGCCAAGTTCGACCCCGATCTTTTTGCCGCCATGGAACAAGAAGCCGTGCGCCAGGAAGAGCACATCGAGCTGATCGCT TCGGAAAACTACACAAGCCCCGCAGTGATGGAAGCTCAGGGCTCGGCGCTGACCAACAAGTATGCCGAAGGTTACCCGGGCAAGCGTTACTACGGTGGTT GCGAGTACGTCGACATCGTTGAACAACTGGCCATCGACCGCGCCAAAGAGCTGTTCGGTGCCGACTACGCCAACGTCCAGCCGCACGCTGGCTCCCAGGC
|
|
| Amino Acid Sequence |
>diguanylate phosphodiesterase
MPTPTASTSSRSVKNSSQLPVRGSLKGALAALVLVMLALLLWQSFEQFQQTQERQRQRSLDYSMQLADRLSLNLTLSAQVSVSLLDEAVSVGQSLEQPST LDNLRQALPALQSVAWLSPAGDIIKDSAMGAGDAAFLKEQLRKAQGKPYYYTNASDGRLVYLLVRQAGGITGDYWALRLGREALKPLTQQPSHDFMHLWR LENRDQSQIIARDGHRSNGNLQTVLLQPISNSDWQLHGLFDARQEREALVLPLIFKCVLAMMFAILPLITLFGLRRRQTQLVESRRRYQGIFEGAGVAIC VLDMSALFTLLDSLQVRNAEDLDRLIKHQPSQFKRLLQQLHITEVNQFALDLLGIENSQQAWDSLIDANPRNPAGPGTRIIRAVLANEPSLELEIRLTRD AGEDQHLWLVMRLPEEQSDYDSVILSIGDITSRKQMELSLLDRESFWSDVVRTVPDHLYVQDVPSQRMIYSNHHLGQTLGYSKTELQSMGEFFWELLLHP DDASNYRDMRLRQRHHGHNELLQCVLRFRDCQQSWRHFDIREQAMAWDKDDQVTRIIGIAKDITHQVTASQSLRDSEQRYRMLAESISDVIFSTDRGLEL NYVSPSVETVLGYSADWIVRNGWSAALANPQQLTGIYSLIVRIRKMLNKPHDLERLRNEVPTRQFVFDCLRADGRKIPIELRLVLVWDEHGSFEGILGVA RDVSQQRRAEKDLRMAATVFEHSTSAILITDPAGYIVQANDAFTRVSGYEVHQILDQLPTLLTVEHEEAHLHQVLRHLNQRGNWEGEVQLKRRNGEQYPA WVGITAVLDDEGDLASYVCFFSDISERKASEQRIHRLAYYDALTHLPNRTLFQDRLHSALQQAERQSAWVVLMFLDLDRFKPINDSLGHAAGDRMLKEMA SRLLACVTDDDTVARMGGDEFTLLLHSGATREVALNRAIHVAEQILNSLVTPFVLEGREFFVTASIGIALSPQDGHELSQLMKNADTAMYHAKERGKNNF QFYQADMNATALERLELESDLRHALEQEEFVLYYQPQFSGDGKRLTGAEALLRWRHPRRGLVPPNDFIPVLEELGLVMEVGDWVLAEACRQLKTWHQERV RVPKVSVNISARQFGDGQLGERIAATLRDTGLPPACLELELTESILMREVGEAMQTLAGLKNLGLSIAVDDFGTGYSSLNYLKQFPIDVLKIDRSFVDGL PSGEQDAQIARAIIAMAHSLNLSVIAEGVETHEQLDFLREHGCDEVQGYLFGRPMPAGQFEAQFSNDALFMLD
BLASTP |
DIAMOND BLASTP (DIAMOND is faster than BLASTP)
Search for conserved domains in this protein at NCBI CDD site
|