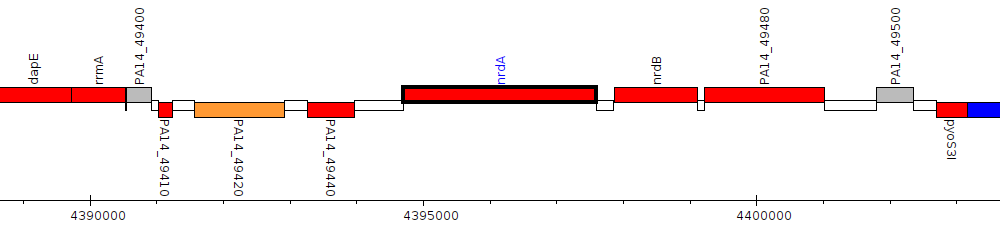
Pseudomonas aeruginosa UCBPP-PA14, PA14_49460 (nrdA)
Cytoplasmic
Cytoplasmic Membrane
Periplasmic
Outer Membrane
Extracellular
Unknown
Sequence Data
| Strain | Pseudomonas aeruginosa UCBPP-PA14 chromosome, complete genome. [Details] | |
| DNA Sequence Upstream of Gene |
ACTCACGCACAGAAGACCCACACTTTATCCACAGGTTTCCCCCAGACTGTCACCTTGCAAACACCCCATTAGCGCATTATCTTGTATCCCCATCGTCGCC ACCCCCTATATCTTGGGTTTCGAGCGCACGAACGGCTACAACGGAACCAACCGCGCACGGACCACTCTGATGGCTCCGGCGGCTCCGCAAAAAAGCATTT TCCAGACGTACTGAAAGCATCGACGGCGCTCACCGCAAGGAGCCCTTCATGACGATGGAAAAGCGGTACGGGTGTTGCAACGGACGCTGTAAACAGACAG TCAACACCACTAGGTATTGTGTTCGACGGCAAAACGCCACGAACCCGCCAGGGCCAGGGAGGCACGCACAGTCCCCACCCTCAGCATTCGAATGAAGCAG CCGCCGCGAGGCCGGCTGCCCGGCTCTTTATCGATTCAAGGGAATGGGCGCCCCGGCGCCCGCTAGCAAAACCATTACGAGAACGTGGAGATACCCACCC
|
|
| DNA Sequence for Gene |
>PA14_49460
|nrdA
ATGCATACCGACACCACACGCGAGAACCCGCAGGCCAGCGCGCCGCAGGCCGCCGATTCGTCGCAGGATCTGGCCGCCACCGCGCCGGGCCAGCTGCGCG TGATCAAGCGCAACGGCACCGTAGTCCCCTACACCGATGACAAGATCACCGTGGCCATCACCAAGGCGTTCCTCGCCGTGGAAGGCGGCACCGCCGCCGC CTCGTCGCGTATCCATGACACCGTGCGCCGCCTGACCGAGCAGGTCACCGCCACCTTCAAGCGCCGCATGCCGTCCGGCGGCACCATCCACATCGAAGAG ATCCAGGACCAGGTCGAACTGGCCCTGATGCGCGCCGGCGAGCAGAAGGTCGCCCGCGACTACGTGATCTACCGCGAAGCCCGCGCCGCCGAGCGCAAGA ACGCCGGCGCCGCCAGCGATGTCGCCCAGCCGCACCCGAGCATCCGCATCACCCGCGCCGACGGCAGCCTGTCGCCGCTGGACATGGGCCGCCTGAACAC CATCATCAGCGAAGCCTGCGAAGGCCTGGCCGAGGTGGACGGCGCGCTGATCGAGCGCGAGACCCTGAAGAACCTCTACGACGGCGTCGCCGAGAAGGAC GTCAACACCGCCCTGGTGATGACCGCGCGCACCCTGGTCGAGCGCGAGCCGAACTACTCCTACGTCACCGCCCGCCTGCTGATGGACACCCTGCGCGCCG AAGCCCTGGGCTTCCTCGGCGTGGCCGAGAGCGCCACCCATCACGAAATGGCCGAGCTGTACGCCAAGGCCCTGCCGGCCTACATCGAGAAAGGCGCCGA GTTCGAGCTGGTCGATGCCAAGCTGAAGGAATTCGACCTGGAGAAACTGGGCAAGGCCATCGATCACGAGCGCGACCAGCAGTTCACCTACCTCGGCCTG CAGACCCTGTACGACCGCTACTTCATCCACAAGGACGGCATCCGCTTCGAACTGCCGCAGATCTTCTTCATGCGCGTGGCCATGGGCCTGGCCATCGAGG AGAAGGACCGCGAGGCACGCGCCATCGAGTTCTACAACCTGCTGTCGTCCTTCGACTACATGAGTTCCACCCCCACCCTGTTCAACGCCGGCACCCTGCG TCCGCAGCTCTCCAGCTGCTACCTGACCACCGTGCCGGACGACCTGTCGGGCATCTACGGCGCCATCCACGACAACGCCATGCTGTCGAAATTCGCCGGC GGCCTGGGCAACGACTGGACCCCGGTGCGCGCGCTGGGCTCCTACATCAAGGGTACCAACGGCAAGTCCCAGGGCGTCGTGCCCTTCCTGAAAGTGGTCA ACGACACCGCGGTCGCGGTCAACCAGGGCGGCAAGCGCAAGGGCGCGGTCTGCGCCTACCTGGAGACCTGGCACCTGGACATCGAGGAATTCCTCGAGCT GCGCAAGAACACCGGTGACGACCGTCGTCGTACCCACGACATGAACACCGCCAACTGGATCCCCGACCTGTTCATGAAGCGCGTCTTCGACGACGGCTCC TGGACCCTCTTCTCGCCGTCCGACGTCCCCGACCTGCACGACCTCTACGGCAAGGCCTTCGAGGAGCGCTACGAGTACTACGAGGCCCTGGCCAGCTACG GCAAGCTGAAGCTGCACAAGGTCGTCCAGGCCAAGGACCTGTGGCGCAAGATGCTCTCCATGCTGTTCGAGACCGGCCACCCGTGGCTGACCTTCAAGGA CCCGTGCAACCTGCGCAGCCCGCAGCAGCACGTGGGCGTGGTGCACAGCTCGAACCTCTGCACCGAGATCACCCTGAACACCAACAAGGACGAGATCGCC GTCTGCAACCTGGGCTCGATCAACCTGGTCAACCACATCGTCGACGGCAAGCTGGACACCGCCAAGCTGGAGAAGACCGTCAAGACCGCGGTACGCATGC TCGATAACGTCATCGACATCAACTACTACTCGGTCCCGCAGGCGCAGAACTCCAACTTCAAGCACCGTCCGGTCGGCCTGGGCATCATGGGCTTCCAGGA CGCCCTGTACCTGCAGCACATCCCCTACGGTTCGGACGCGGCCATCGCCTTCGCCGACCAGTCCATGGAAGCCATCAGCTACTACGCGATCCAGGCTTCC TGCGACCTGGCCGACGAGCGCGGCGCCTACCAGACCTTCCAGGGCTCGCTGTGGTCGCAAGGCATCCTGCCGATCGACTCGGAGAAGAAGCTGATCGAAG AGCGCGGCGCCAAGTACATCGAAGTCGACCTGTCGGAAACCCTCGACTGGGCGCCGCTGCGCGAGCGCGTACAGAAAGGCATCCGCAACTCGAACATCAT GGCCATCGCGCCGACCGCGACCATCGCCAACATCACCGGCGTCTCGCAGTCGATCGAGCCGACCTACCAGAACCTGTACGTGAAGTCGAACCTCTCCGGC GAGTTCACCGTGATCAACCCCTACCTGGTGCGCGACCTCAAGGCCCGCGGCCTGTGGGACCCGGTCATGGTCAACGACCTGAAGTACTACGACGGTTCCG TGCAGCAGATCGAGCGCATCCCGCAGGACCTCAAGGACCTCTACGCCACCGCGTTCGAAGTCGAGACCCGCTGGATCGTCGAAGCCGCCAGCCGTCGCCA GAAGTGGATCGACCAGGCCCAGTCGCTGAACCTGTACATCGCCGGCGCCTCGGGCAAGAAGCTCGACGTGACCTACCGCATGGCCTGGTTCCGCGGCCTG AAGACCACCTACTACCTCCGTGCCCTGGCCGCCACCAGCACCGAGAAGTCCACCATCAACACCGGCAAGCTCAACGCCGTGTCGGCCGGTGGCAACGACG GCCTGCAAGCCGCCCCGGCCGCCGAGCCGAAGCCGGCGCCGGTGCCGCAGGCATGCAGCATCGATAACCCCGACTGCGAAGCCTGCCAGTGA
BLASTN Search
|
DIAMOND BLASTX Search (DIAMOND is faster than BLASTX)
|
|
| DNA Sequence Downstream of Gene |
TCGCGCGTCGCTGAACGGCGTCCGTGTCGTGGCCGGGCAAGCCGGACTCCTCGAGTGGGTCCGGCTTGCCCGGCGCCTGACGGTCGCTCGTCCAGCGCCA CGCTGGCAGCGCAAGGCCCCTCGCCAAGGCCAGGAACAATCCCCTTCTTCCCTCCGGGGGAGAAGAACGGCCCGGCCAGACCGTGCCGGACCACCGCTTT CGCGTGCACCTCACGCCCCATATCCAGGCCGCCGAGACGGCCGCCAGACCAGGAGAGAGCAAGATGCTGAGCTGGGACGAATTCGACAAAGAAGACCCGA CCGAAGCCAAGGCCGCGCCCGCCGCCGCCCAGGCCGTTGCCCAGGGCCATGACAAGCTGGACGACGAAGCCGCCGGCTCGGTGGAAGAAGCGCGCGCCGT TTCCGCCGACGACTCCGACGCTGTCGCCCGCGCCAAGAAGGCCCTGAACGACCTCGACATCCAGGAAGGCCTGGACGACCTCGAAGGCTCCGCCGCGCGC
|
|
| Amino Acid Sequence |
>ribonucleotide-diphosphate reductase subunit alpha
MHTDTTRENPQASAPQAADSSQDLAATAPGQLRVIKRNGTVVPYTDDKITVAITKAFLAVEGGTAAASSRIHDTVRRLTEQVTATFKRRMPSGGTIHIEE IQDQVELALMRAGEQKVARDYVIYREARAAERKNAGAASDVAQPHPSIRITRADGSLSPLDMGRLNTIISEACEGLAEVDGALIERETLKNLYDGVAEKD VNTALVMTARTLVEREPNYSYVTARLLMDTLRAEALGFLGVAESATHHEMAELYAKALPAYIEKGAEFELVDAKLKEFDLEKLGKAIDHERDQQFTYLGL QTLYDRYFIHKDGIRFELPQIFFMRVAMGLAIEEKDREARAIEFYNLLSSFDYMSSTPTLFNAGTLRPQLSSCYLTTVPDDLSGIYGAIHDNAMLSKFAG GLGNDWTPVRALGSYIKGTNGKSQGVVPFLKVVNDTAVAVNQGGKRKGAVCAYLETWHLDIEEFLELRKNTGDDRRRTHDMNTANWIPDLFMKRVFDDGS WTLFSPSDVPDLHDLYGKAFEERYEYYEALASYGKLKLHKVVQAKDLWRKMLSMLFETGHPWLTFKDPCNLRSPQQHVGVVHSSNLCTEITLNTNKDEIA VCNLGSINLVNHIVDGKLDTAKLEKTVKTAVRMLDNVIDINYYSVPQAQNSNFKHRPVGLGIMGFQDALYLQHIPYGSDAAIAFADQSMEAISYYAIQAS CDLADERGAYQTFQGSLWSQGILPIDSEKKLIEERGAKYIEVDLSETLDWAPLRERVQKGIRNSNIMAIAPTATIANITGVSQSIEPTYQNLYVKSNLSG EFTVINPYLVRDLKARGLWDPVMVNDLKYYDGSVQQIERIPQDLKDLYATAFEVETRWIVEAASRRQKWIDQAQSLNLYIAGASGKKLDVTYRMAWFRGL KTTYYLRALAATSTEKSTINTGKLNAVSAGGNDGLQAAPAAEPKPAPVPQACSIDNPDCEACQ
BLASTP |
DIAMOND BLASTP (DIAMOND is faster than BLASTP)
Search for conserved domains in this protein at NCBI CDD site
|