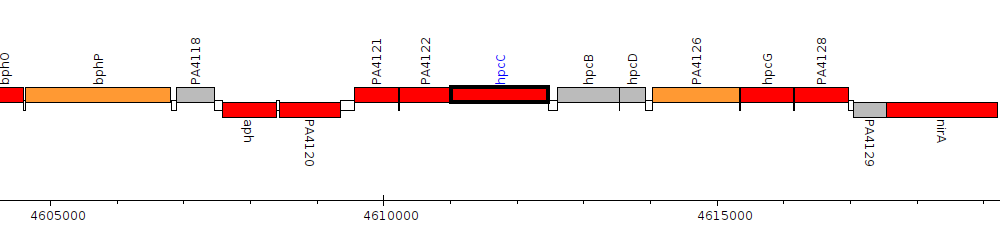
Pseudomonas aeruginosa PAO1, PA4123 (hpcC)
Cytoplasmic
Cytoplasmic Membrane
Periplasmic
Outer Membrane
Extracellular
Unknown
Sequence Data
| Strain | Pseudomonas aeruginosa PAO1 chromosome, complete genome. [Details] | |
| DNA Sequence Upstream of Gene |
TACATGCACTACGAGTGCGAACTGGTGGCGGTGATCGGCAAGCCGGCGCGCAACGTCCGCCGCGAGGACGCCCTCGGCTACCTGGCCGGCTACACGGTGT GCAACGACTACGCGATCCGCGACTACCTGGAGAACTACTACCGGCCCAACCTGCGGGTGAAGAACCGCGACGCCACCACCCCGGTGGGGCCGTGGATCGT CGACGCGGCCGAGGTTCCCGAGCCGAACCGGCTGACCCTGCGCACCTGGGTCAACGGCGAGCTGCGCCAGGAAGGCAGCACCGCGGACATGATCTTCGAC ATTCCCTACCTGATCGAATACTTCTCCAGCTTCATGACCCTGCAGCCGGGCGACATGATCGCCACCGGCACCCCGGAAGGCCTGTCCGACGTGGTCCCCG GCGACGAAGTGGTGGTGGAGGTGGAGGGCGTCGGTCGCCTGGTCAACCGAATCGTCAGCGAGGCCGAATTCTTCCGCGCCCGCGCACAGGAGCACGCAGA
|
|
| DNA Sequence for Gene |
>PA4123
|hpcC
ATGATCAAACACTGGATCAATGGCCGCGAGGTCGAAAGCAAGGACGTCTTCGAGAACTACAACCCGGCCACCGGCGAGCTGATCGGCGAGGTCGCCAGCG GCGGCGCGGCGGAAATCGACGCGGCGGTGGCGGCGGCCCGGGAAGCCTTCCCGAAATGGGCCAATACCCCGGCCAAGGAGCGCGCGCGCCTGATGCGCCG GCTCGGCGAGCTGATCGACCGGAACGTGCCGCACCTGGCGGAACTTGAGACCCTCGACACCGGCCTGCCGATCCACCAGACGAAGAACGTGCTGATCCCG CGCGCCTCGCACAACTTCGAGTTCTTCGCCGAAGTCTGCACGCGGATGAACGGGCACAGCTATCCGGTCGACGACCAGATGCTCAACTACACCCTGTACC AGCCGGTAGGCGTCTGCGGCCTGGTCTCGCCGTGGAACGTACCGTTCATGACCGCCACCTGGAAGACCGCGCCGTGCCTGGCGCTGGGCAACACGGCGGT GCTGAAGATGTCCGAGCTGTCGCCGCTGACCGCCAACGAGCTGGGCCGCCTGGTGCACGAGGCGGGCATTCCGCCGGGGGTGTTCAACGTGGTCCAGGGC TACGGCGCCAGCGCCGGCGACGCGCTGGTTCGCCACCGCGACGTGCGCGCGGTGTCCTTCACCGGCGGCACCGCCACCGGGCGACGGATCATGGAGGCGG CCGGGATCAAGAAATACTCGATGGAACTGGGCGGCAAGTCGCCGGTGCTGGTCTTCGAAGACGCCGACCTCGAGCGGGCGCTGGACGCCGCTCTGTTCAC CATCTTCTCGCTGAACGGCGAGCGCTGCACCGCCGGCAGTCGCATCTTCGTCCAGGAAAGCGTCTACCCGCAGTTCGTCGCCGAGTTCGCCGCGCGCGCC AGGCGCCTGATCGTCGGCGATCCGCAGGACCCGAAGACCCAGGTCGGCTCGATGATCACCCAGGCCCACTACGACAAGGTCACCGGCTACATCCGCATCG GCCTCGAGGAAGGCGCCACCCTGGTGGCCGGCGGCCTGGAGCGTCCGGCCGGCCTGCCGGCGCACCTGAGCAAGGGGCAGTTCATCCAGCCCACGGTGTT CGCCGACGTGGACAACCGCATGCGCATCGCCCAGGAGGAGATCTTCGGCCCGGTGGTCTGCCTGATCCCGTTCAAGGACGAAGCCGAGGCGCTGCGCCTG GCCAACGACGTGGAATACGGCCTGGCCTCCTACATCTGGACCCAGGACATCGGCAAGGCCCATCGCCTGGCACGCGGCATCGAGGCCGGGATGGTCTTCA TCAACAGCCAGAACGTGCGCGACCTGCGCCAGCCGTTCGGCGGGGTGAAGGCCTCGGGCACCGGACGCGAAGGCGGGGAATACAGCTTCGAGGTATTCGC CGAGATCAAGAACGTGTGTATATCCATGGGCAGCCATCACATCCCCCGCTGGGGCGTGTAG
BLASTN Search
|
DIAMOND BLASTX Search (DIAMOND is faster than BLASTX)
|
|
| DNA Sequence Downstream of Gene |
GGCGCGCTCGTGCAGAGCGGCCGCCCGAGGCCGCCAGCAGCGCCGGCGTGCAGACACAATCAGAAGAATCCGGGCCAGCCGCCAACGGCCGCGCCCGCTG CCAGGCCCAACGGGCCACCAGGAGAATCGTCATGGGCAAAGTCGCTCTGGCTGCCAAGATCACCCACGTACCCTCGCTGTACCTGTCCGAGCTGCCCGGC CCGCGCCACGGCTGCCGCCAGCCGGCGATCGACGGGCACCGCGAGATCGGCCGGCGCTGCCGCGAACTGGGGGTCGACACCATCGTGGTGTTCGACACCC ACTGGCTGGTCAACGCCGGCTACCACATCAACTGCGCGCCGCACTTCGAGGGGCTCTACACCAGCAACGAGTTGCCGCACTTCATCGCCAACATGGAGTA CGGCTTCCCCGGCAACCCGGAGCTGGGCCGCATCCTCGCCGAGGGCTGCAACGCGCTCGGCGTGGAGACCCTGGCCCACGACGCCACCACCCTCGGCCCG
|
|
| Amino Acid Sequence |
>5-carboxy-2-hydroxymuconate semialdehyde dehydrogenase
MIKHWINGREVESKDVFENYNPATGELIGEVASGGAAEIDAAVAAAREAFPKWANTPAKERARLMRRLGELIDRNVPHLAELETLDTGLPIHQTKNVLIP RASHNFEFFAEVCTRMNGHSYPVDDQMLNYTLYQPVGVCGLVSPWNVPFMTATWKTAPCLALGNTAVLKMSELSPLTANELGRLVHEAGIPPGVFNVVQG YGASAGDALVRHRDVRAVSFTGGTATGRRIMEAAGIKKYSMELGGKSPVLVFEDADLERALDAALFTIFSLNGERCTAGSRIFVQESVYPQFVAEFAARA RRLIVGDPQDPKTQVGSMITQAHYDKVTGYIRIGLEEGATLVAGGLERPAGLPAHLSKGQFIQPTVFADVDNRMRIAQEEIFGPVVCLIPFKDEAEALRL ANDVEYGLASYIWTQDIGKAHRLARGIEAGMVFINSQNVRDLRQPFGGVKASGTGREGGEYSFEVFAEIKNVCISMGSHHIPRWGV
BLASTP |
DIAMOND BLASTP (DIAMOND is faster than BLASTP)
Search for conserved domains in this protein at NCBI CDD site
|