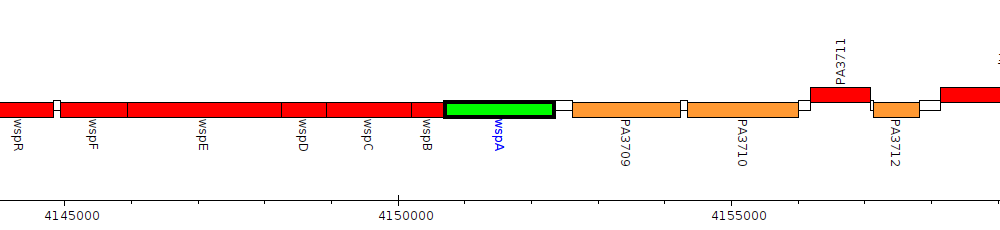
Pseudomonas aeruginosa PAO1, PA3708 (wspA)
Cytoplasmic
Cytoplasmic Membrane
Periplasmic
Outer Membrane
Extracellular
Unknown
Sequence Data
| Strain | Pseudomonas aeruginosa PAO1 chromosome, complete genome. [Details] | |
| DNA Sequence Upstream of Gene |
GCGCTGATGGTCGAACTGTTCCCGACCCGCATCCGCTATTCCTCGCTGTCCCTGCCGTACCACATCGGCAACGGCTGGTTCGGCGGCTTCCTGCCCACGG TCTCGTTCGCCCTGGTGGTGTACACCGGCGACATCTTCTACGGCCTCTGGTATCCGGTGCTGATCACCGGCGGTAGCCTGGTCTGCGCCTTGCTGTTCCT CCGCGAAACCCGCCATACCGACATCCACCGGTGAAATCGCGCCCCGTTCCCGGCATGGGGACGGGGCGCACATTCCCTCCGTGATGAGCCTGTCTTCTCA GAAAAGTCTGGCTTGCCAGTTTTCTTTCTTTCTCTTTCTGCCACACTTCTGGCGTCAAAAAACGCCTTTCCAGCGCCTACAATAGCGGGAAAACCCTATG GCGCTGCTTGCCGGTGCCGGGGACGGCCTATACAGTCCGCGCGATTGACGGGCCGTTGTGGCGGCAGGAACGAATCCGGACTCGAGTCTTGGGGAAAAAT
|
|
| DNA Sequence for Gene |
>PA3708
|wspA
GTGAAGAACTGGACTGTTCGCCAGCGAATCCTGGCAAGTTTCGCCGTGATCATCGCGATCATGCTGCTGATGGCCGCTACTGCGTACGTGAAGATGTTGA CGGTGGAAAAGGGCGCCTACCGTGTCCAGGACGACGCCATGCCGGGGATGTACTTCATCACGCTGGTACGCAGTTCGTGGACCGACAACTACTTGCAGAC CCAGGAACTGTTCGGCATCACCGACGACCACGAGCTGAGCAAGGCCGAGGCCGACAGTATCCTCGCCAGCGAGGAGCGCCTGGACCAGCAGATCGCCTCC TACCAGAAGACCATGAACCCGGACGAGGCCCGCGACCACGAGTTGCTCGCCGGTTTCCAGGCCGTGCGCAAGGACTACCTGGAGCAGCACGACAAGGTGC TCGAGCTTTACCGCGAGAAGCGCTTCGAGGAAGCCGGCAAGCTCGTCGCCGGCCCGTTGACCGAGCACTGGCGCGAGGGCCGCAAGTACCTCAACGAGAT GATCGAGCTGAACAAGGACATCGCCGATCGCGCCTCGGACAACATCGTAAACGCGGTGGACGATGCCGAACTGAGCATGCTGGTGACCCTGCTGCTGGCG GTGGTGGTAGCCGGCATCTGCGGTTTCCTGCTGTTGCGGGCGATCACCCAGCCGATCCAGAAGATCGTCCGCAGCCTCGACCTGATGGCCGGTGGCGACC TCACCGCACGCCTGAACCTCGGCCGGCGTGACGAATTCGGCGCCATCGAGACCGGTTTCAACGGCATGGCCGAAGAGCTCAAGGGCCTGGTGTCGCAGGC CCAGCGTTCTTCGGTGCAGGTCACCACCTCGGTCACCGAGATCGCCGCGACCTCCAAGCAGCAGCAGGCCACCGCCACCGAAACCGCCGCGACCACCACG GAGATCGGCGCCACTTCTCGCGAGATCGCCGCCACCTCGCGCGACCTGGTGCGGACCATGAGCGAAGTCTCCGGCGCCGCCGAGCAGACGTCGACCCTGG CCGGTTCCGGCCAGTTGGGCCTGGCGCGCATGGAGGAAACCATGCACCACGTGATGGGCGCGGCCGACCTGGTCAACGCCAAGCTGGCGATCCTCAACGA GAAGGCCGGCAACATCAACCAGGTGGTCACCACCATCGTCAAGGTCGCCGACCAGACCAACCTGCTCTCGCTGAACGCCGCCATCGAGGCGGAGAAAGCC GGCGAGTACGGCCGCGGGTTCGCCGTGGTGGCCACCGAGGTGCGCCGGCTGGCGGACCAGACCGCGGTCGCCACCTACGACATCGAGCAGATGGTGCGCG AGATCCAGTCGGCGGTATCGGCCGGGGTGATGGGCATGGACAAGTTCTCCGAGGAGGTCCGCCGCGGTATCGCCGAGGTCGGCCAGGTCGGCGAGCAACT GTCGCAGATCATCCAGCAGGTGCAGGCGCTGGCGCCGCGGGTGCAGATGGTCAACGAGGGTATGCAGGCCCAGGCTACCGGTGCCGAGCAGATCAACCAG GCGCTGGTGCAACTGGGCGAGGCCACCGGGCAGACCGTGGAGTCGCTGCGCCAGGCCAGCTTCGCCATCGATGAGCTGAACCTGGTGGCGAACGGGCTGC GCAACGGCGTATCCCGCTTCAAAGTCTGA
BLASTN Search
|
DIAMOND BLASTX Search (DIAMOND is faster than BLASTX)
|
|
| DNA Sequence Downstream of Gene |
GGCTGTGACCGTGTCCCGCTCCACCGGCGATCATCGACGCACCAGCAAGCTGTTCCTGCTGTTCCGCATGGAAGGCGACCGCTATGCCCTGGATGCCCGT GAAGTGGTCGAAGTGCTGCCGCTGCTGCGCCTGAAGCGCATTCCGGAGGCGCCGGAATGGGTCGCCGGGGTGTTCTCCCATCGCGGCGTCCTGGTCCCGG TGCTCGACCTCTGCGCAATGGCCTTCGGCCGCGCGGCGCTGGCCCGAACCAGCACGCGCATCGTGCTGGTCGAATACCGCGCCCGCCAGGACCGGGAGCC GGTCTGGCTCGGACTGATCCTCGAACAGGCCACCGATACCCTGCGCTGCGAACCGTCGGCGTTCCGCGACTATGGCCTGGACAACGGCGGGGCCCGCTAT CTCGGTCCGGTCTATGAAGGACCACGGGGACTGGTGCAATGGGTGCGGGTCGAGGCATTGCTGCCCGACGAAGTGCGCGCCCTGCTGTTCCCGCCGGAGT
|
|
| Amino Acid Sequence |
>probable chemotaxis transducer
MKNWTVRQRILASFAVIIAIMLLMAATAYVKMLTVEKGAYRVQDDAMPGMYFITLVRSSWTDNYLQTQELFGITDDHELSKAEADSILASEERLDQQIAS YQKTMNPDEARDHELLAGFQAVRKDYLEQHDKVLELYREKRFEEAGKLVAGPLTEHWREGRKYLNEMIELNKDIADRASDNIVNAVDDAELSMLVTLLLA VVVAGICGFLLLRAITQPIQKIVRSLDLMAGGDLTARLNLGRRDEFGAIETGFNGMAEELKGLVSQAQRSSVQVTTSVTEIAATSKQQQATATETAATTT EIGATSREIAATSRDLVRTMSEVSGAAEQTSTLAGSGQLGLARMEETMHHVMGAADLVNAKLAILNEKAGNINQVVTTIVKVADQTNLLSLNAAIEAEKA GEYGRGFAVVATEVRRLADQTAVATYDIEQMVREIQSAVSAGVMGMDKFSEEVRRGIAEVGQVGEQLSQIIQQVQALAPRVQMVNEGMQAQATGAEQINQ ALVQLGEATGQTVESLRQASFAIDELNLVANGLRNGVSRFKV
BLASTP |
DIAMOND BLASTP (DIAMOND is faster than BLASTP)
Search for conserved domains in this protein at NCBI CDD site
|