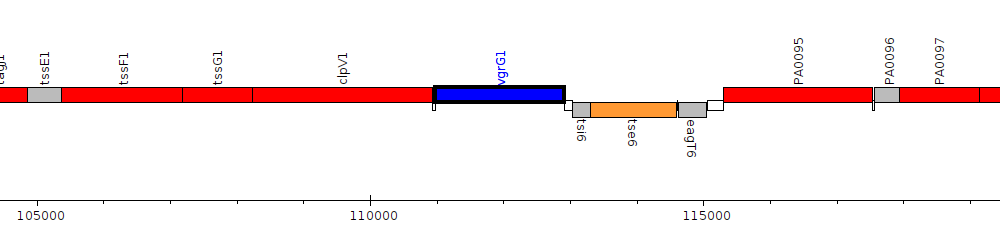
Pseudomonas aeruginosa PAO1, PA0091 (vgrG1)
Cytoplasmic
Cytoplasmic Membrane
Periplasmic
Outer Membrane
Extracellular
Unknown
Sequence Data
| Strain | Pseudomonas aeruginosa PAO1 chromosome, complete genome. [Details] | |
| DNA Sequence Upstream of Gene |
CACCAACGCCGGCACCGAGATGATCGCCAGCCTCTGCGCCGATCCGGAACTGATGCCCGAGCCGGAAGCCATCGCCAAGTCGCTGCGCGAACCGCTGCTG AAGATCTTCCCGCCGGCGCTGCTCGGCCGCCTGGTGACCATCCCCTACTACCCGCTCAGCGACGACATGCTCAAGGCCATTTCGCGCCTGCAACTGGGGC GGATCAAGAAGCGCGTGGAGGCGACCCACAAGGTGCCGTTCGAGTTCGACGAGGGCGTCGTCGACCTGATCGTCTCGCGCTGCACCGAGACCGAGAGCGG CGGCCGGATGATCGACGCGATCCTCACCAACACGCTGTTGCCGGACATGAGCCGCGAGTTCCTCACCCGCATGCTCGAAGGCAAGCCGTTGGCCGGGGTA CGTATCAGTAGCCGCGACAACCAGTTCCACTACGACTTCGCCGAGGCCGAGTGACAACCGGCGACACGCAGAGCAGTAGAAGGAACCGTCGATGGGATTG
|
|
| DNA Sequence for Gene |
>PA0091
|vgrG1
ATGCAACTGACCCGCCTGGTCCAGGTGGATTGCCCGCTGGGGCCGGACGTGCTGCTGTTGCAGCGCATGGAGGGACGCGAGGAACTGGGACGGCTGTTCG CCTACGAGCTGCACCTGGTATCGGAAAATCCCAACCTGCCGCTGGAGCAGTTGCTCGGCAAGCCGATGAGCCTGTCGCTGGAGCTGCCCGGCGGCAGCCG GCGCTTCTTTCACGGCATCGTCGCGCGCTGTAGCCAGGTGGCCGGGCACGGCCAGTTCGCCGGCTACCAGGCCACCCTGCGGCCCTGGCCGTGGCTGCTG ACGCGCACCTCGGACTGCCGCATCTTCCAGAACCAGAGCGTGCCGGAGATCATCAAGCAGGTGTTCCGCAACCTCGGCTTTTCCGATTTCGAGGATGCCC TCACGCGCCCCTACCGCGAGTGGGAATACTGCGTGCAGTACCGCGAGACCAGCTTCGACTTCATCAGCCGGCTGATGGAACAGGAAGGCATCTACTACTG GTTCCGCCATGAGCAGAAGCGCCACATCCTGGTGCTCTCCGACGCCTACGGCGCGCATCGCAGCCCGGGTGGCTACGCCAGCGTGCCGTACTACCCGCCG ACCCTCGGCCATCGCGAGCGCGACCACTTCTTCGACTGGCAGATGGCACGCGAGGTCCAGCCCGGTTCGCTGACCCTCAACGACTACGACTTCCAGCGCC CCGGCGCGCGCCTGGAGGTGCGTTCGAACATCGCCCGGCCGCACGCGGCGGCCGACTACCCGCTGTACGACTATCCCGGCGAATACGTGCAGAGCCAGGA CGGCGAGCAGTACGCGCGCAACCGCATCGAGGCGATCCAGGCGCAGCACGAGCGCGTGCGCCTGCGCGGCGTGGTGCGCGGGATCGGCGCCGGGCACCTG TTCCGCCTGAGCGGCTATCCGCGCGATGACCAGAACCGCGAGTACCTGGTGGTCGGCGCCGAATACCGGGTGGTCCAGGAACTCTACGAAACCGGCAGCG GCGGCGCCGGCTCGCAGTTCGAGAGCGAGCTGGACTGCATCGACGCCAGCCAGTCGTTCCGTCTCCTGCCGCAGACTCCGGTACCGGTGGTGCGGGGTCC GCAGACCGCGGTGGTGGTCGGACCCAAGGGCGAGGAGATCTGGACCGACCAGTACGGCCGGGTCAAGGTGCACTTCCACTGGGATCGCCACGACCAGTCG AACGAGAACAGCTCCTGCTGGATTCGCGTGTCCCAGGCCTGGGCCGGGAAGAACTGGGGTTCGATGCAGATCCCGCGGATCGGCCAGGAAGTGATCGTCA GCTTCCTCGAAGGCGACCCGGACCGGCCGATCATCACCGGGCGGGTCTACAACGCCGAGCAGACGGTGCCCTACGAGCTGCCGGCGAACGCCACCCAGAG CGGGATGAAGAGCCGTTCGAGCAAGGGCGGCACGCCGGCCAACTTCAACGAGATCCGCATGGAGGACAAGAAGGGCGCCGAGCAGTTATACATCCACGCC GAGCGCAACCAGGACAACCTGGTCGAGAACGATGCCTCGCTGTCGGTCGGCCACGACCGCAACAAGAGCATCGGCCACGACGAGCTGGCGCGCATCGGCA ACAACCGCACCCGCGCGGTGAAGCTCAACGACACCCTGTTGGTGGGCGGGGCGAAGAGCGACAGCGTCACCGGCACCTACCTGATCGAGGCCGGCGCGCA GATCCGCCTGGTCTGCGGCAAGAGCGTGGTGGAGTTCAACGCCGACGGCACCATCAATATCTCCGGCAGCGCCTTCAACCTCTACGCCAGCGGCAACGGC AACATCGACACCGGCGGCCGCCTCGACCTCAATTCCGGCGGCGCCAGCGAGGTCGACGCCAAGGGCAAGGGCGTGCAGGGCACCATCGACGGCCAGGTAC AGGCGATGTTTCCGCCGCCGGCGAAGGGCTGA
BLASTN Search
|
DIAMOND BLASTX Search (DIAMOND is faster than BLASTX)
|
|
| DNA Sequence Downstream of Gene |
GGCGGCGGCATCCTGGCTGCCCGCCCTTGGGCAGGACGCCGCGGGAGCCTTGACGATTCGCGCATGTCCTCGCCAGGCAGAAGCGGCGGTCGCTCAAGAC CGATGGTGTTGCGCTCAGGGCAGATCGACCTTCAGGCCGCGGCCAGTGCGTATACCGACGTAGTAGGCGTCCTTGAGGGCCCTGGAGAGTTCCGGGTCGG TTTCGTCGAATTCCTTCACGGCGATGCTGCCGAGGGTCAACCGGTGCAGTGCGGAACGATCCAGGCTGCGGTCGAGCAGGACGGACCTGATGTACTGCAA TTGCTTTTCCGCAGACAGCAGGACCTCGTATCCCGGATAGCGGGCCAGCCGGTCGACGACCAGCGCCAGAGCGCGGTCGATGTATTCGATGGGTGTCATG ATCCCTCCCGGGGAAGCAGACCGAAGGAGCCTTTCTCGTTGGAGAACAGTTGTTGCGCGCCGCCTTTGGCGGGATATGACTGTCCCTTTACCGACCAGAA
|
|
| Amino Acid Sequence |
>VgrG1
MQLTRLVQVDCPLGPDVLLLQRMEGREELGRLFAYELHLVSENPNLPLEQLLGKPMSLSLELPGGSRRFFHGIVARCSQVAGHGQFAGYQATLRPWPWLL TRTSDCRIFQNQSVPEIIKQVFRNLGFSDFEDALTRPYREWEYCVQYRETSFDFISRLMEQEGIYYWFRHEQKRHILVLSDAYGAHRSPGGYASVPYYPP TLGHRERDHFFDWQMAREVQPGSLTLNDYDFQRPGARLEVRSNIARPHAAADYPLYDYPGEYVQSQDGEQYARNRIEAIQAQHERVRLRGVVRGIGAGHL FRLSGYPRDDQNREYLVVGAEYRVVQELYETGSGGAGSQFESELDCIDASQSFRLLPQTPVPVVRGPQTAVVVGPKGEEIWTDQYGRVKVHFHWDRHDQS NENSSCWIRVSQAWAGKNWGSMQIPRIGQEVIVSFLEGDPDRPIITGRVYNAEQTVPYELPANATQSGMKSRSSKGGTPANFNEIRMEDKKGAEQLYIHA ERNQDNLVENDASLSVGHDRNKSIGHDELARIGNNRTRAVKLNDTLLVGGAKSDSVTGTYLIEAGAQIRLVCGKSVVEFNADGTINISGSAFNLYASGNG NIDTGGRLDLNSGGASEVDAKGKGVQGTIDGQVQAMFPPPAKG
BLASTP |
DIAMOND BLASTP (DIAMOND is faster than BLASTP)
Search for conserved domains in this protein at NCBI CDD site
|