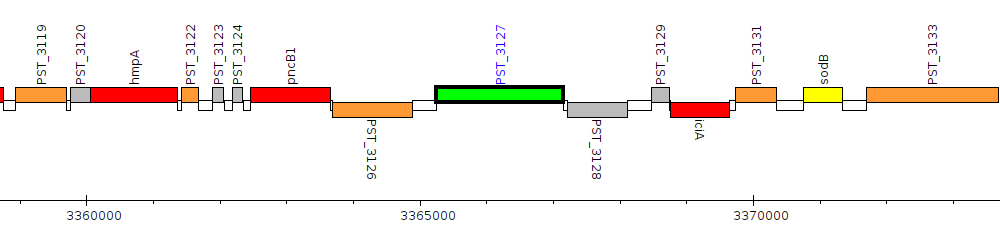
Pseudomonas stutzeri A1501, PST_3127
Cytoplasmic
Cytoplasmic Membrane
Periplasmic
Outer Membrane
Extracellular
Unknown
Sequence Data
| Strain | Pseudomonas stutzeri A1501 chromosome, complete genome. [Details] | |
| DNA Sequence Upstream of Gene |
GTTGACGATCAGCGTCGCCCTGCGCTGGCAGAGCAGCAACGGATGGCGACCCGGCGTCAGCAGATGGCGCAGTTCATTGGGCTTGAGTTCGCTGGGCAGC AGCGTTGTCAGGCGGTTGAGCAGCAAATCAAGGGGCGATGGCATCTTATTGTTGTGCTCCCAGCTGGGACGGTCTATTCGCAGCAGGCACGCCTCCGGCG ACTCCCGAATACCGATGGCGGCTCTTCAATCCATTTCAAAGCGGCGACTACTCGGCAGGGCGAAAGCATCACCCCAGGCGCAAGCGGAGCCGATGGTAGC CAGTTGACCCCAGCATTCCCTTGAGCCAGGACAATGAATTGATTGCAAACAGCCATTACTTCCTTAGAGGTAGCGCCACTGAGGAACAATCGCCCTTTTG AGCGCTTATCGGCACGGACACCAGCCAGTAGCGTGACCGGGTCGCCCGCCCCGTCTGCGAGTCGACGTATCCACAAAAAGAACAATAAGGAGATACCCCC
|
|
| DNA Sequence for Gene |
>PST_3127
GTGCAAAGCGCTCTCAAGCCGCTTGCGGCAGCCGTTCTGCTCACCTGCGTGTCCAGCGTCGCTACTGCCGATAGCGGGCCGTTCAGCCAGTTCATCGTAT TCGGCGACTCGCTGAGCGATGCGGGCAATTTTCCGGATCTGCAAAGCCCGACGCTCGGCGGCAACCCCACCGGGGGGTTGCGCTTCACCAACCGCACCGG CCCCACCTACGGACCGGGCGAATACATCGGCGAGGTCGGCACCCAACGACTGGCCGGCATGCTGGGTCTGCAGTCCCTGCCATCCACACCGCTGCTGCCG GCGCTGCTGACTGGCAACCCCGACGGGACCAACTATGCAGTGGGCGGTTACCGTACCGATCAAATACTCGACTCGATAAACGGCGACTCCATCGTCGAGG TAGGCGGCCTTAGCCGTACCCGACCCGGTTATCTGCGGGAAAATCCGCGAGTCGACAGCAATGCCCTGTATTACCTGAACGGTGGCGGCAACGACATCTT CCAGCTCAACACCAACCCGGTGACCATGGCCCAAGCCGCGAGCAATCTGGTGGCTGGCGTCGGCGCCCTGCAGGCAGCAGGAGCGCGCTACATCATCGTT TCCGATCTGCCCGACGTCGGTACCACGCCGTTGGGCGCCTTCACCGGGCAGGCTGCGACGTTCAACTTCCTGAGCGACCAGTTCAATGCCGAGCTGGCCA GCCAACTGCAAGCCCAGGGCGGCAACTACGTACTGGTGAACAATCGCCTGCTGCTCGCCGAGGTGCGCGCTGATCTGGCGGCGTTCGGCTTCGACCCCAA CGTGGCGCAGACCGCAGTGTGTTTCGACGCGTCGGCCGGCAACTGCCAGGCTGATCCGGTTTACAGCCTCGGCGGCAGCGCGCCGGACCCAAGCCGCCTG CTGTTCAACGACGCCGTGCATCCCACCACCGCGGTTCACCAGATCAGCGCCGACTACCTCTATTCAATCCTGTCCGCGCCCTGGGAAGTCTCGCTGCTGC CGGAGATGGGCCGCTCCGCATTGCGCGCCCACCTGCAGCAGCTGGACACCGAGCTGGCCGCCCTGCGTGGCGATTGGCAACCGGTCGGCGCGTGGCGCAC CTTCGTTCAGGGCGGTTACAACCGACCTGAGTACGACGGTTACGGTGGTGGAGACGGACATGGTCTGAGCCTGTCGCTGGGTGTTACCCATCGACTGAGC GAAGCCTGGCTGGCCGGCGTCAGCCTCGGGCTGGCGGAAAACTCGCTGGAGCTGGGTCGAAACGACTCCGACTACGACATGCGCAGCTATCTGGCCACGG CGTTCGCCCGTTACGAGTATCAGCGCCTGTTCGCTGACTTCAGCCTCAGCGCAGGCTACCTGGACTACCACGACCTGAAGCGCACCTTCGCCCTCGGCAT CACCGAGCGCACGGAAAAGGGCGACACCGAGGGAACCCTCTGGGGCGCCGCGGTGAAGACCGGCTTCAACCTGATGCAGCCGGGCGATCGCCTGCAGTTC GGGCCGTTCATCGGTGCCAGCTACCAGAAAGTGGACGTCGACGGATACAGCGAGAAAGGCGCCCGTTCCACCACCCTGAGCTATGACGATCAGGAACTGG ACTCGCTACGCCTGTCGCTCGGCCTGTTCGGCGACTATGCCCTGACCGAACGCACGCGACTGTTCGGCGAGGTGGCACGGGAGGTGGAACGCGAGGATGA GGACCGCCGCGACTTGCGCATGTCCTTGAACAGCGTGCCGGGCAACAGTTTCGAACTGCCCGGAGCGGTGCCGACCGGCGACCAGACACGTTTCAGCGTT GGCCTGACGCACCGTCTGACGCCCGGCCTGGCGCTGCGTGCCAATTACCATTACCGCGGAAACGACAACCGCGACCACGGGCTCGGACTGTCGCTGGCCT TGGATCTGTAG
BLASTN Search
|
DIAMOND BLASTX Search (DIAMOND is faster than BLASTX)
|
|
| DNA Sequence Downstream of Gene |
AGGGAGACGCTCAAAGGCCGCCGCCGCGAATGCGCGCGGCGGCCGAGCGCGGCGAACTCAGCGCCCGTCGATCTGCCCTTGCAGGTTGGCAATCTGCCCC TGCATGGCGTTGATGGTGCGAGTGACCTGGGCGCGGAAGGAATCGAATTCGGCGGTATTGGTATTGTTGGCAGGCGCCGGACGGTTTTCCAGTTCGCTGC GCAGCACCAGGATGTCCTGCTCCAGACGGCTGATCGCCTGACTCTGGTTACCACCCTGCTTGAGCGCCGCCACGTCCTTGCTCAGGCTGTCGATCCGTCC GGCCAGCTTGGCCTGCTCGTCCAGCGCAGACTTCAGCGTGGCCTGCTCGCTACCGAGGGTCTTGACCGTCTCGGCCAGCGATGCGGTGGTGCCCTGCTGG CTCTGCACGTCGGCCCCCAGCCGCTCCAGGCGCTTGCCCTGCTCTTCCATGCGCTGATCCTGATTGCCTTGCCGGCCGGCCAGGCTCTGCTGCTCGGTGG
|
|
| Amino Acid Sequence |
>esterase EstA
MQSALKPLAAAVLLTCVSSVATADSGPFSQFIVFGDSLSDAGNFPDLQSPTLGGNPTGGLRFTNRTGPTYGPGEYIGEVGTQRLAGMLGLQSLPSTPLLP ALLTGNPDGTNYAVGGYRTDQILDSINGDSIVEVGGLSRTRPGYLRENPRVDSNALYYLNGGGNDIFQLNTNPVTMAQAASNLVAGVGALQAAGARYIIV SDLPDVGTTPLGAFTGQAATFNFLSDQFNAELASQLQAQGGNYVLVNNRLLLAEVRADLAAFGFDPNVAQTAVCFDASAGNCQADPVYSLGGSAPDPSRL LFNDAVHPTTAVHQISADYLYSILSAPWEVSLLPEMGRSALRAHLQQLDTELAALRGDWQPVGAWRTFVQGGYNRPEYDGYGGGDGHGLSLSLGVTHRLS EAWLAGVSLGLAENSLELGRNDSDYDMRSYLATAFARYEYQRLFADFSLSAGYLDYHDLKRTFALGITERTEKGDTEGTLWGAAVKTGFNLMQPGDRLQF GPFIGASYQKVDVDGYSEKGARSTTLSYDDQELDSLRLSLGLFGDYALTERTRLFGEVAREVEREDEDRRDLRMSLNSVPGNSFELPGAVPTGDQTRFSV GLTHRLTPGLALRANYHYRGNDNRDHGLGLSLALDL
BLASTP |
DIAMOND BLASTP (DIAMOND is faster than BLASTP)
Search for conserved domains in this protein at NCBI CDD site
|