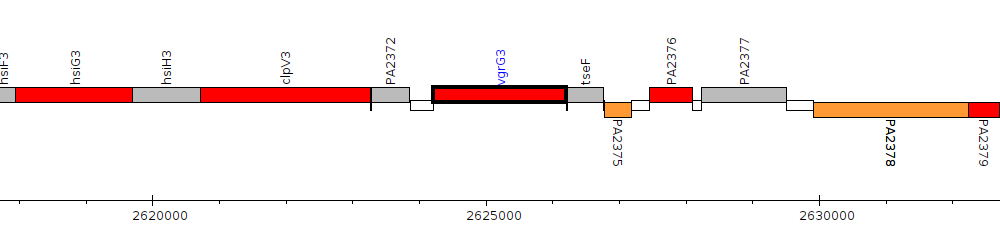
Pseudomonas aeruginosa PAO1, PA2373 (vgrG3)
Cytoplasmic
Cytoplasmic Membrane
Periplasmic
Outer Membrane
Extracellular
Unknown
Sequence Data
| Strain | Pseudomonas aeruginosa PAO1 chromosome, complete genome. [Details] | |
| DNA Sequence Upstream of Gene |
ATAGATGTATATTACTATAATTCATCGGTGTCGGTACCGAAAGAGTTTGCCGACGGCAATTACCATAAAGACGGGGTACTCTTTGATGCGCAAGGCAATG TAGTGCTAACGCCAAGATTTCGAGCTTCGGAAGCAAGACAGAGAGTACCTTAAGAATAATTTAGCGCCATCTCAAATAAAAAGGAAACGAGTAATGGGAT ATCTATTTTTTGACACTTCATAACCACAAAATAAGCCTCCTCCATCCCCCTTTATGAACTCTGACCAAGTCACCATTATGGCGCTGAAATTCTGGTCTGG AACGTACAGCACATGGACAACCAATCCACATCCACTCATTCGATGGCCTTTTGGGAAAAGCTGGAGTTCCTCGACAATACTTGGCCAACCGATGAGGAGC GATCATTTTCCGGTGATCTATACGTGGATGGAAAAATCGGGATGAAGGTCGTCTTGAGGTTATTCATCATTCCTTCGGGCTGGCATGACAAGGCACACTA
|
|
| DNA Sequence for Gene |
>PA2373
|vgrG3
ATGCCCCGTCCCACCGACACCAATACCACCCTCTCCCTCAGCGCCTCCACCCTGGGTGATCTTTACCCCCAGACGCTTTCCGGGGGCGAGGCGTTGAACG AGCTGGGCAGCCTGACGCTCGGCGGCTACAGCGCCACCGCGCTGACGTTGAGCAATGCGGTGGCCACCCATCTCACCGCCACCCTGCACAACGACGCCGA CCAGCGTCCGCTCGACGGCCTGGTCGCGGAGATCCGCCAACTCCCCGGCGATGCCAGCGCCGAGCGCTACCAGGTGCTGTTGCGCCCCTGGCTCTGGTGG CTGACGCTGGCCAGCAACAACCGGGTGTTCCAGAACCTGGCCACCAGCGACATCGTCACCCAGGTCTTCGACCAGCACGGCTTCAGCGACTACCAGTTGC AGCTCAGCGGCAGCTACCAGCCCCGCGAATACTGCGTGCAGTACGGCGAGAGCGATCTCGCCTTCGTTTCGCGGCTGCTGGAGGAAGACGGCATCTTCTG GTTCTTCACCCATGCCGCCGGCAAGCACACCCTGGTGCTGGCCGACAGCAACGACGCCTTCCCGCCGATTCCCAACGGCCCGCAAGTGGCCTACCTGGGC CAAGGAATCGGCGTGCGCGAGTTGCAGGGCGTGCGTTCGGCGCAGTACAGCCTCCAGGCGGTATCCGGGACCTACAGCGCCACCGACTACGAGTTCACCA CCCCGGGCACCTCGCTGTACTCCCAGGCCGAGGCGGTTTCCGGCGCCGCCGGCGTCTACCAGCACCCCGGCGGCTACACCGCCAAGGCCCAGGGCGACAG CCTGACCAAGCAACGCATCGACGGCCTGCGCAGCCAGGAGACGCGCCTGATCGGCGAGAGCGACTGCCGCTGGCTGGTGCCCGGCCACTGGTTCACCCTC AGCGGGCATGACGACGATTCGCTGAATATCGACTGGGTGCTGACCTCGGTCACCCATGACGCCAGTCACGCGCACTACCGCAACCGCTTCGAGGCGATCC CCAAGGCCACCGCCTACCGCCCCGCGCGGGTCACGCCCAAGCCGCGCATGCACACCCAGACCGCCCTGGTGGTGGGCAAGGCCGGCGAGGAGATCTGGAC CGACCAGTACGGCCGGATCAAGATCCAGTTCCCCTGGGACCGCGACGGCAAGAACGACGAGACCTCCTCCTGCTGGGTGCGCGTGGTGCTGCCCTGGAGC GGCAAGGGCTTCGGCATGCAGTTCGTGCCGCGCATCGGCCAGGAAGTGATCGTCACCTTCATCGACGGCGACCCGGACCGCCCGCTGGTCACCGGCTGCG TCTACAACGGCGACAACGCCCTGCCCTACGCGCTGCCGGACAACCAGACGCAGTCCGGGATCAAGACCAACTCGTCGAAGGGCGGCGGCGGTTTCAACGA GCTGCGCTTCGAGGACAAGAAGGACGCCGAGGAAGTCTTCCTCCAGGCGCAGAAGGACCTCAACGTCAACGTGCTCAACGACAGCACCGCCAGCATCGGC CACGACGAGACCCTGACGGTGCAGAACGCCCGCACCCGCACGGTGAAGGAAGGCGACGAGACCGTCACCCTGGAGAAAGGCAAGCGCACGGTGACCATCC AGACCGGCAGCGACAGTCTGGATGTGAAGGACACGCGCACGGTGACGGTGGGCGCCGACCAGACCCACAGCACCGGCGGCAACTACAGCCACAAAGTCAG CGGCAACTTCGAGCTGACGGTGGACGGCAACCTGACCATCAAGGTCAGCGGCACCCTCGCCCTGCAGAGCGGCGGCAGCCTGACCCTGAAGAGCGACGCC GACCTCGCCGCCCAGGCTGGCACCTCGCTGACCAGCAAGGCCGGGACGTCGCTGACCAACCAGGCCGGCACCTCCCTCACCAACAAGGCCGGCACCAGCC TGACCAACGATGCCGGCGTCAGCCTGACCAACAAGGCCGGCGCCGAACAGACGGTGGACGGCGGCGGCATGCTGACCATCAAGGGCGGCCTGGTAAAGGT CAACTGA
BLASTN Search
|
DIAMOND BLASTX Search (DIAMOND is faster than BLASTX)
|
|
| DNA Sequence Downstream of Gene |
GGAGAAGCGCATGGCGGCATCCGGCAAGCTCGACCTGGTTCGTGGCGACAGCCATCTCGCCGGCAACCTGCTCGACGGCAGCCTGGAAGGCCCGTTGCGC ATCGACGAGCACGACAGGCCGCAGGCCAGCCTCGGCTACCGGCAGGGCCAGTTGCACGGCGCCAGCACCCTGTTCCATCCCAACGGCAAGGTCTCCGCGC AACTCGCCTTCGTCGACGGCAAGCTGCACGGGCCGGCGAGTTTCCATGCCGCGGAAGGCTGGTTGCAGCGCAAGGCGCACTACCGCAACGGGCTGCTCCA CGGCGAAGCGTTCAACTATTTCGCCAACGGCCAGGTGGCCGAGCGCGAGCATTACCGCGACGGCGTGCGCGACGGGGTCTACCAGCGCTTCCATGGCAAT GGCCAACTGGCCTTCGACGGACGCTACCTGAACGGCCAGCTACTGGACGGCGCCCAGCCGTTCGCCGACGACGGCCGGCCGCTGGACAGCGAGGGCAAGC
|
|
| Amino Acid Sequence |
>VgrG3
MPRPTDTNTTLSLSASTLGDLYPQTLSGGEALNELGSLTLGGYSATALTLSNAVATHLTATLHNDADQRPLDGLVAEIRQLPGDASAERYQVLLRPWLWW LTLASNNRVFQNLATSDIVTQVFDQHGFSDYQLQLSGSYQPREYCVQYGESDLAFVSRLLEEDGIFWFFTHAAGKHTLVLADSNDAFPPIPNGPQVAYLG QGIGVRELQGVRSAQYSLQAVSGTYSATDYEFTTPGTSLYSQAEAVSGAAGVYQHPGGYTAKAQGDSLTKQRIDGLRSQETRLIGESDCRWLVPGHWFTL SGHDDDSLNIDWVLTSVTHDASHAHYRNRFEAIPKATAYRPARVTPKPRMHTQTALVVGKAGEEIWTDQYGRIKIQFPWDRDGKNDETSSCWVRVVLPWS GKGFGMQFVPRIGQEVIVTFIDGDPDRPLVTGCVYNGDNALPYALPDNQTQSGIKTNSSKGGGGFNELRFEDKKDAEEVFLQAQKDLNVNVLNDSTASIG HDETLTVQNARTRTVKEGDETVTLEKGKRTVTIQTGSDSLDVKDTRTVTVGADQTHSTGGNYSHKVSGNFELTVDGNLTIKVSGTLALQSGGSLTLKSDA DLAAQAGTSLTSKAGTSLTNQAGTSLTNKAGTSLTNDAGVSLTNKAGAEQTVDGGGMLTIKGGLVKVN
BLASTP |
DIAMOND BLASTP (DIAMOND is faster than BLASTP)
Search for conserved domains in this protein at NCBI CDD site
|